



Introduction to Artificial Neural Networks
Bruno B.
2019-05-23
8min
Development
This blog is about presenting one of the biggest growing trends in IT today - the mythical Artificial Intelligence, known as AI. Will it kill us?

Share this blog:
One of the biggest growing trends in IT today is the mythical Artificial Intelligence, known as AI. A lot of people want to use it, a lot of people talk about it, a lot of very influential people even claim it will soon rise against us in a Terminatoresque scenario.
The common denominator in all the people just being bombarded with all of that information is that they actually don’t know what AI is. I will try to demystify one of the most popular AI mechanisms. The neural network.
Neural networks are the leading technique in one of two main approaches to AI. The connectionist approach is based upon a belief that people do not have symbolic knowledge stored inside their brains, but rather just neuron connections that activate, process, and store information that can then be used to activate new connections and that way derive new information. This approach has brought us a connectionist black-box model that are neural networks.
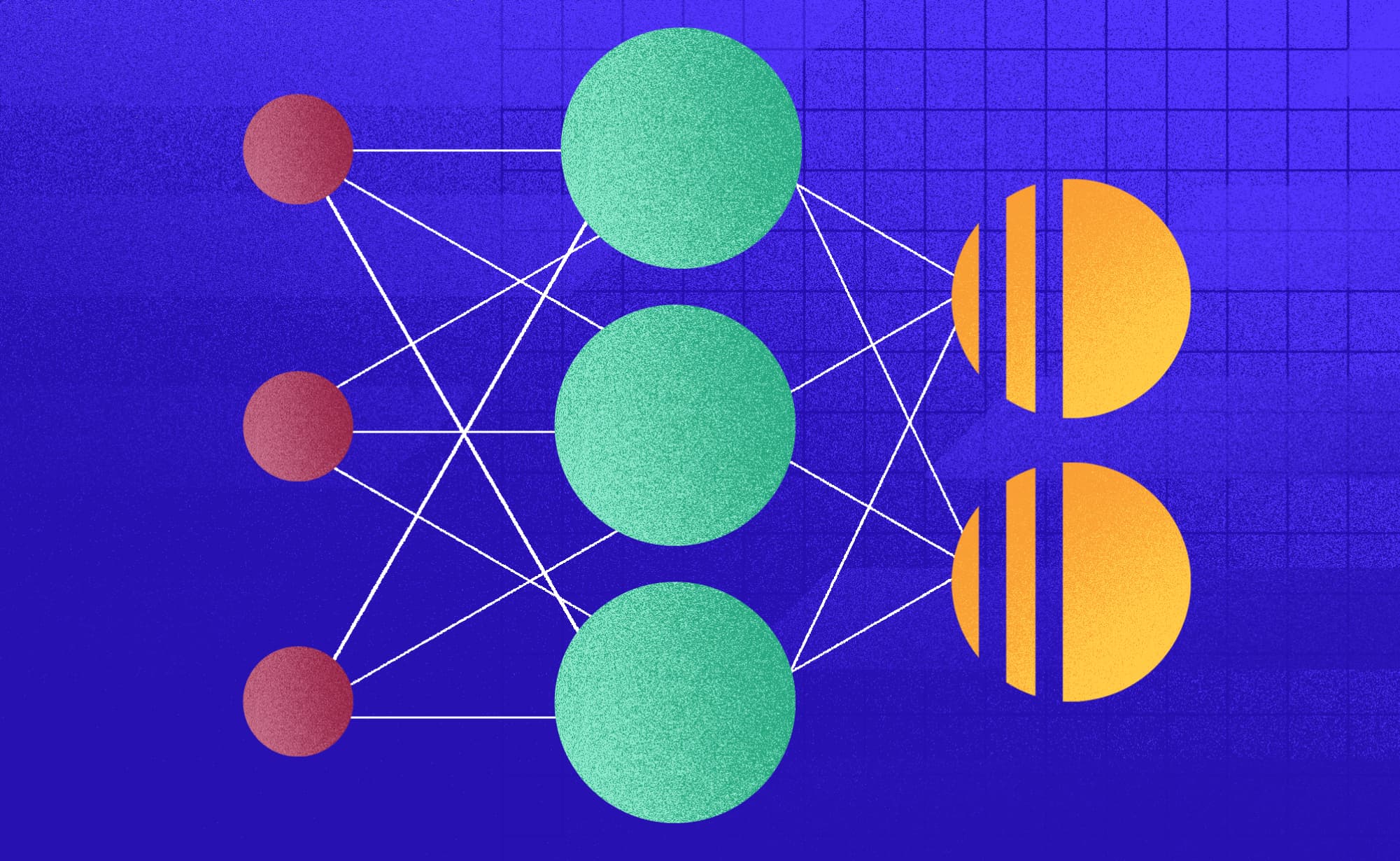
Artificial neuron
To model an artificial neural network first thing we need is a component that builds the neural networks in our brain. This idea has its roots way in the start of computer science so the first model of an artificial neuron was created by Warren McCulloch and Walter Pits in 1948.
The neuron consists of a few integral parts that we try to model by imitating their behavior with mathematical operations and functions. Dendrites are the input part of a neuron which allows it to receive signals from a large number of neighboring neurons, and in the computational model, it is implemented as an input vector of numbers. To determine the amount of signal to be received by the neuron, we use a weight vector in the computational model, and a natural neuron uses synaptic neurotransmitters on the end of its dendrites. The weight vector achieves its purpose by multiplying the input vector while synaptic neurotransmitters produce similar behavior with chemical reactions.
Signals are then combined in the soma of the neuron, or in the computational model, all the values in the product of the weight and the input vector are feed to a summation function which adds them all to one value. Artificial neuron also adds a new summation factor to this equation, as it has a bias value that does not come from the input vector.
After all the values or signals are added, the neuron is to transmit them to its output. Axon is the part of a biological neuron that activates when a certain amount of electrical potential in the signals is achieved and it then triggers to send the signal to the neurons connected to it. To achieve the same behavior, in the artificial neuron we use an activation function. It is a mathematical function, which usually produces an output value between -1 and 1. There are many activation functions that are used in implementations of neural networks and the choice of an activation function is important to maximize the efficiency of a neural network.


So the important parts of an artificial neuron are the input vector, weight vector, bias, summation function, and the activation function which produces an output vector. A lot of vectors hold a lot of numbers. And what to do with an artificial neuron, how does a bunch of them form a network? The answer to this is layers.
Making a network
Artificial neural networks consist of layers of artificial neurons. A layer is a group of neurons that get activated at the same time during the propagation of data through the network. To build an artificial neural network we need an input layer, any number of hidden layers, and an output layer. The input and the output layer are like an interface that the network uses to communicate with the outside world – its users. The input layer has to be the same size as is the input data format, to achieve a scenario where each neuron is fed exactly one value from the input vector.
The output layer has a format we chose to make our data interpretable. For example, if the goal is to classify a photo and there are 10 different groups in which we can classify it the output layer will produce a vector of 10 values. Each of these values is the possibility that a picture contains an object represented by that classification group. Hidden layers do not have any restrictions about their size and there can be any number of them.

The output layer has a format we chose to make our data interpretable. For example, if the goal is to classify a photo and there are 10 different groups in which we can classify it the output layer will produce a vector of 10 values. Each of these values is the possibility that a picture contains an object represented by that classification group. Hidden layers do not have any restrictions about their size and there can be any number of them.
How do they learn?
Since neural networks don’t have and can’t even efficiently hold any expressive knowledge such as if a photo is turquoise-white and has a mirrored N then it shows a Cinnamon logo, but could eventually successfully determine that fact, there must be another way.
The answer to that problem is training. As a data-driven model, neural networks don’t hold any knowledge once they are successfully implemented. To gain “knowledge” they undergo a number of classifications/predictions/whatever they do on an already labeled dataset. After each classification, the result is compared with the correct result provided by the dataset. The difference between those two results is determined with a loss/error function, and an error is calculated. Then we use that error to modify the values in weight vectors. The most popular way to do that is by using the error backpropagation algorithm popularized by a group of authors (with Geoffrey Hinton as the most famous one) in the year of 1986. The first papers on backpropagation were published in the 1960s, but even the one in 1986 was far ahead of its time with proper computing power to execute this algorithm being available to a wide range of users only in the 2010s.

The algorithm uses mathematics to determine the influence of each element of each weight vector and each bias value in the creation of the output error. Then it updates the values of the weights and biases according to their individual errors. That way neural network strives to minimize the error over time.
The problem with this approach is known as overfitting. Since we only subject a neural network to one batch of data it can get overly trained to processing only these already known entities. During the process of its training, we can imagine that a neural network derives some general features at first, but with a large number of repetitions the features get more and more specific, which is not a desirable behavior in this case. Overfitted models produce inferior results in processing new, never-seen data. Since the goal of training a neural network is for it to process new, never seen data with the knowledge extracted from its training, overfitting is not at all a pleasant side-effect. To solve this problem, we divide our dataset into several subgroups to make the training more efficient and avoid overfitting.
First, we divide the dataset into a training, validation, and testing set. For example, the division ratio could be 60:20:20, respectively. The training set is used to train the neural network, and for that reason, the largest part of the dataset should fall into it. The validation set is used for frequent evaluation of the neural networks efficiency. The testing group is used to evaluate the overall efficiency once the training is done. This way when we see that the error percentage is still dropping on the training set but starts growing on the validation set we can stop the training and reduce the overfitting of our model.
In conclusion...
Neural networks are efficient in carrying out specific tasks, but as a way to general AI or singularity, they do not seem like a promising approach. There are also many improvements on this artificial neural network by adding other types of layers or making them reuse the data they already processed in a recursive manner, which make neural networks able to carry out even more types of specific tasks. To form a complex and more diverse system, a number of specialized neural networks can be combined with their output data then used by some other algorithm and that way carry out a more general or a more complex task.
As they are one of the most developed techniques in implementing Artificial Intelligence, and not even smart enough to know what they are doing, it is safe to assume that they are not a threat to mankind, nor is any AI system implemented to this day. Also, there is no magic inside them, just pure mathematics and data-driven optimizations. So, in the end, they are good guys, classifying your pictures and predicting your stock prices in the next quarter, and not at all plotting the apocalypse of mankind.
Share this blog:
Subscribe to our newsletter
We send bi-weekly blogs on design, technology and business topics.
Similar blogs


Development
Matej Musap
2025-08-18
3min
Beyond the Buzz: How Developers Are Using AI in Real Projects
Development
Matej Musap
2025-07-28
2min
How a Template Project Helps Us Guarantee Code Quality and Team Stability

Sales
Mladen Šimić
2025-06-24
3min

